LSP 与 VS Code 插件开发(二)语义构建
这是《LSP 与 VS Code 插件开发》系列文章的第二篇。
第一篇:语言服务器架构
第二篇:语义构建
第三篇:语言服务器协议
第四篇:开发小技巧
上一章我们讲到,语言服务器的输入是源码,而输出是结构化的数据。代码编辑器(客户端)某个位置显示什么颜色,鼠标悬浮到某个位置提示什么信息,都由客户端向语言服务器请求,获取数据后,渲染到用户界面。
因此语言服务器需要编译源码,构建语义模型,为客户端提供智能编程服务。
所谓的 编译 是怎么回事?它和编译器是什么关系?本章会和大学里的编译原理知识有些关系,但保证比课本上的更有趣、更好玩!
语言服务器与编译器的关系
先回顾一下编译原理的基本流程:词法分析 -> 语法分析 -> 语义分析 -> 中间代码生成 -> 代码优化 -> 目标代码生成 -> ...
前端相似
具体各流程的作用就不赘述了,大学课本里那些长篇大论介绍 LL(1) 文法过于乏味。
我们基本可以把编译器的工作分为前端、(中端)、后端几个流程,事实上,编译器和语言服务器在编译的过程中,前端的过程是非常相似的。也就是 词法分析、语法分析、语义分析 几个阶段。
通过这三个阶段,从源码中获取语义信息后,语言服务器等待客户端请求,为编程体验服务,而编译器则是继续中端、后端,为生成目标产物服务。在这之后,两种做的事情就大相径庭了。
换句话说,对于 console.log 这一行代码,两者都经历了这样的阶段:
| 阶段 | 进度 |
|---|---|
| 源码 | console.log |
| 词法分析 | IDENTIFIER DOT IDENTIFIER |
| 语法分析 | 规约为 DomainDotAccess,是通过点号访问域的语法 |
| 语义分析 | console 符号是一个接口,log 符号是其中一个方法 |
这里的 DomainDotAccess 是个示意,实际上可能是 MemberExpression 或者 PropertyAccessExpression 之类的,只是一个命名问题。
接下来,有了语义信息后,语言服务器就可以:
- 前 7 个字母涂成红色;后三个字母涂成蓝色
console.log-> console.log - 鼠标悬停到后三个字母的位置,提示
Prints to stdout with newline. - 校验实际参数的数量、类型是否与函数签名相符、返回值类型是否正确
- …
而这些都是和编译器完全无关的事情。

容错
此外,两者的容错处理也是不一样的。当源码中出现了错误:
编译器会停止编译,通过标准输出等方式抛出编译错误,自然也没有目标产物的输出了,当然,一行代码的改动可能引起数个文件的错误,如果只遇到一个错误就停止编译,也不利于 debug,往往会尝试尽可能多的抛出错误;
而用户会持续不断的编码,你可以想一下,输入编写一行代码时,可能只有输入了最后一个分号 ; 后,编译才会通过,而这期间语言服务器则会持续工作,进程不会停止,而是收集 Diagnostic,也就是诊断信息,客户端根据这些信息,在代码编辑器上显示红色或者橙色的波浪线。
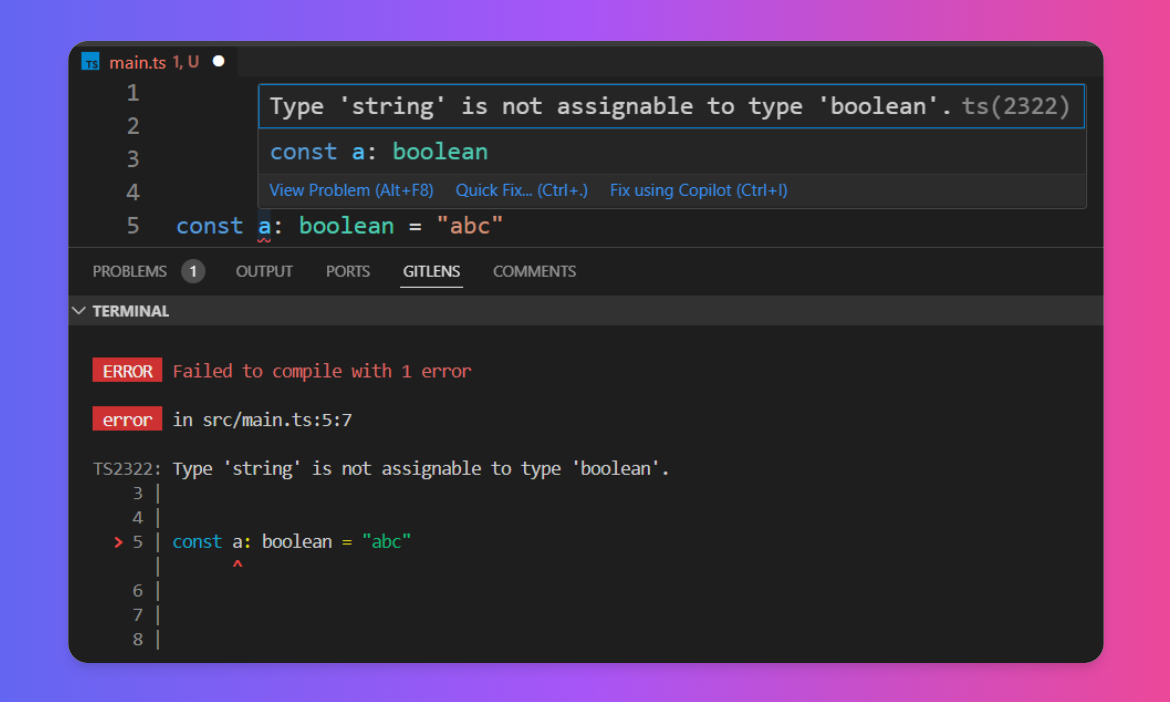
通常来说,编译器能顺利编译通过的工程,语言服务器也不应出现诊断。反过来,代码编辑器中没有波浪线,理论上编译也是能过的。
碰到代码编辑器中标红,但能编译通过的情况倒是还好,如果代码编辑器没问题,但编译时报错,那就痛苦了。这种一般都是由于编译器和语言服务器没有统一编译标准导致的,可能是两者编译配置不同,同样一段代码,语言服务器认为是 warning,但编译器认为是 error,甚至是两者的语言版本不同(比如 python2 和 python3)。
另外,像 VS Code 这样的编辑器都支持插件,可能除了语言官方的语言服务器,还有别的(例如 lint 工具)在同时工作,这也会导致代码编辑器里看到的诊断比编译输出的多。从这个角度上,编译器和语言服务器的一致性也是工程化的一个重要问题。
这里可以看到,语言服务器的工作和运行时是无关的。换句话说,使用记事本写的 Hello World,没有语言服务器参与,经过编译器编译后,同样可以执行,而语言服务器提供的只是更好的编码体验,也就是 DX(developer experience)。
总的来说,编译器面向运行时一次性执行,要求最终正确性和可执行性,而语言服务器在用户编码时持续服务,要求及时性和友好性。
使用同一种语言构建
上一章提到,语言服务器与编译器往往是同一种编程语言构建的程序。现在你应该更理解了,在编译原理前端,两者的逻辑高度相似,往后才开始异化。使用同一种语言,甚至在同一个工程中,能最大的复用代码,减少维护成本。这也是促成语言服务器架构的原因之一。
事实上很多语言或是编译器内置语言服务器,例如 Deno、TypeScript ,或是在内置工具链中就有语言服务器,例如 Go 和 Gopls、Rust 和 RLS。
当然,语言服务器的实现也并不仅是官方一种,VS Code 就受不了 PHP 解析器不能容错,直接新写了一个语言服务器
深入理解语法与语义
刚才提到了语法分析和语义分析,这里再举几个例子详细说明下。
十六进制颜色字面量
假设我们要设计一门新的编程语言,支持十六进制的颜色字面量值。方案如下:
语法:定义为井号 # 后跟多个十六进制字符(0-9, a-f, A-F)。
语义:仅长度为 3 (rgb)、4(rgba)、6(rrggbb)或者 8(rrggbbaa)的十六进制序列视为合法颜色值。
从语法上没有约束十六进制字符数量。好处在于语法规则宽松,便于解析和扩展,并且容错友好。
一套语法描述可能复用于编译器、语言服务器、lint 工具等多个软件,而由于软件功能不同,语义实现则各不相同。因此语法设计应该更宽松和易扩展。
1 | 合法,白色 |
类型推导和显式类型声明
再举一个变量定义的例子
1 | var a = 5 |
a 的值是 5,类型是整数。这里没有显式的声明 a 的类型,因此是通过等号右边的表达式的类型推导出来的。
右值是一个字面量,词法分析时可以通过正则匹配之类的方法得知它是一个 token,比如叫 INT_DIGIT。接着语法分析时,得知 INT_DIGIT 就是一个普通的字面量表达式。然后语义分析时,就知道一个整数字面量表达式的类型是整数,这是编程语言运行时就定义好的,无需额外的语法声明的(typeof 5 == "int")。
与之对应的,如果给 a 加了显式的类型声明:
1 | var a int = 5 |
那么语法上就是通过等号左边的 int token,在语义上查找符号表得知是整数类型。接着和右值类型比较,发现是一致的,这样就通过了类型检查。
不论是类型推导或者显示声明类型,a 的类型都是基于词法分析后根据语法结构决定的。前者是分析了字面量值 5 的语义,为整数;后者是分析了类型符号 int 的语义,同样是整数。这两个过程都是基于语法分析,判断语义。
语法错误更为严重
语法错误的影响更严重,例如少了半个括号,会影响后续也许是整个文件的代码的作用域。相比来说,语义错误更可控,能尽量避免蝴蝶效应。
例如这样的 Go 代码,bar 是一个键为 int,值为 string 的字典。

现在有两个典型的语义错误,分别在第 11 行,尝试用整数字面量赋值给 string 类型;和 13 行,尝试将 string 值赋值给 int 类型。
现在我们制造一个语法错误,删掉第 9 行的一个右括号 ],这显然是一个简单的编码失误,但语言服务器不干了,没有正确的语法支持,很难继续构建语义,第 11 行、第 13 行的红色波浪线也消失了。

一个简单的语法错误,导致了整个文件的语义分析失败,这是语法错误的严重性。而且报出的错误信息也只能基于语法,和代码改动毫无关系,这简直是新手的噩梦。
顺便提一句,其实有经验的开发者一眼就能看出问题所在,但而基于编译原理的解析程序则难以做到这一点。我认为这也许会是大语言模型的一个应用场景,结合代码编辑器,帮助代码初学者快速定位语法错误。
语法错误更快出现
语义错误通常比语法错误更晚出现,因为语法错误出现在语法分析阶段,而语义错误在之后的语义分析阶段。
通常编译单个文件,已经能得到完整的语法错误信息,而语义错误可能需要等整个工程的编译才能完全收集到。
例如,有些编程语言里支持“严格模式”,用来增强类型检查、避免隐式错误等。它在语法上可能就是一行字符串字面量或者魔法注释,例如 "use strict" 或者 // @ts-check。它们自身没有语法错误,但是加上这行代码会影响后续成千上万行代码的语义分析,带来数个语义错误。
这里有一个提高语言服务器性能的方法:
将语言服务器拆分成两个,一个面向语法,一个面向语义。
语法服务器很轻量,只负责词法分析、语法分析,有语法错误时立即反馈诊断。另外也可以提供一些完全基于语法的,和语义无关的小功能,例如显示颜色。
语义服务器更重,负责全部的语义构建和服务。
将语法诊断和其他小功能从语义服务器中剥离,可以降低语义服务器的开销,也能让轻量的功能更快的反馈给用户。
当然,这不是说语义服务器就不做词法、语法分析了,依然会做,甚至尝试容错,但会更专注在和语义相关的功能上。
Vue 的语言服务器就是这么做的。
语义模型
这里展示一下我做的基于 Node 的语言服务器,编译这段代码后得到的语义模型
1 | graph test { |
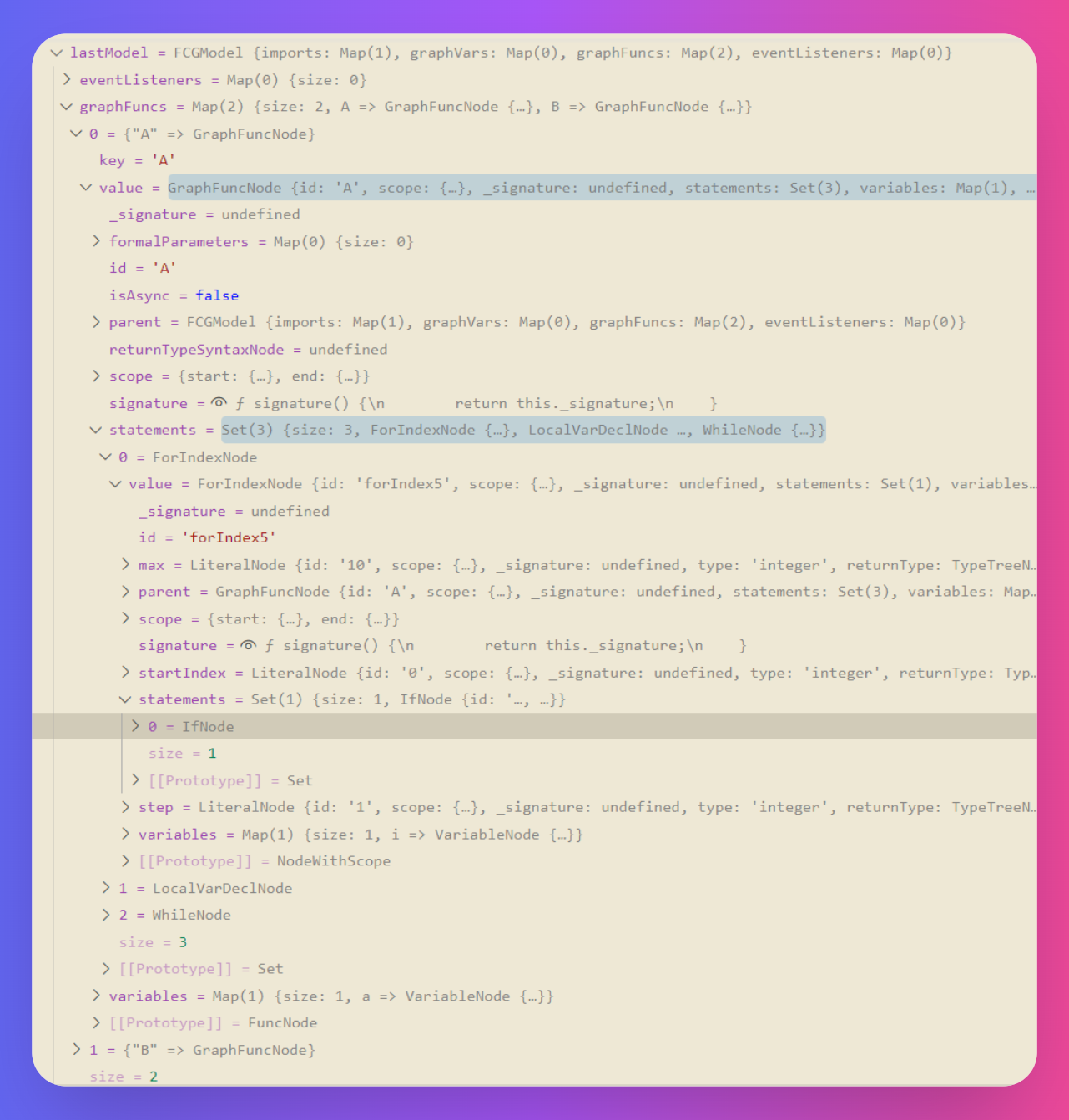
这是一门自研的 DSL 语言,其具体的语义就不做讨论了,但可以看到,在 Node 内存中,我的语义模型是一个大的对象,graph、func、for、if、while 关键字分别开辟了新的作用域,它们层层嵌套,形成一颗树结构。
既然是树结构,深度优先遍历算法就是可行的。第 4 行的 if 语句,要从根节点开始经过 root -> func A -> for -> if 几个语法节点,才能访问的到。
鼠标移动到第 5 行的 LogInfo 上,就要经过上述的深度优先搜索,根据鼠标位置的行列号,一层一层查找语义模型,得知此位置的语义是一个函数名,悬浮提示出函数签名,按 F12 还能跳转到函数声明的地方。
这个在树结构上层层查找的过程,有点类似语法分析中由上至下的递归下降分析法,从非终结符开始,递归展开,直到终结符;或者反过来,从终结符开始,递归折叠,直到非终结符。但两者还是有本质区别的,语法分析是为了构建语法树,而语义分析是基于语法树,构建语义模型。只不过从实现上,这个语义模型也是一个树结构的,毕竟是基于语法,两者的结构也是相似的。
shadow 机制
有了这个形象的树形结构,我们就可以从新的角度理解编程语言中的 shadow 机制。shadow 机制通常指在当前作用域和外层作用域中,同名变量的优先级问题。
1 | func A() { |
第 8 行的 foo 变量最终的值会是 12,也就是改变了第 6 行的 foo,即使外层还有两个同名变量。
在语义分析阶段,第 8 行是一个加法赋值语句,右值是 10,左值是一个符号 x。为了找到这个符号的语义,语言服务器会从语义模型中当前光标位置的就近作用域开始寻找,也就是 if 开辟的作用域中,发现符号表中有一个 foo,它的语义是 int 类型的变量。这样,第 8 行的 foo 符号就是一个变量的语义了,也许会变成 variable 的蓝色;而它的定义位置,根据符号表,得知在第 6 行,按 F12 跳转到定义,光标就会跳转到第 6 行。
另外,得知第 8 行 foo 的语义后,还会做一系列的语义检查,常见的编程语言可能会检查:
foo是可写的局部变量,可以作为左值foo是个整数,可以做加法赋值- 右值是个整数字面量,和左值的类型相同,可以赋值
- …
shadow 机制对于代码补全也有积极意义:在 if 代码块中,输入 fo,语言服务器应该仅列出一个 foo 变量,忽略外层的两个。让我们给最外层的 foo 改名叫 foo001
1 | func A() { |
这时候就会补全 if 中的 foo 和外层的 foo001,而不会再出现 while 中的 foo。

总结
现在,我们明白了语言服务器想要提供智能编程服务,首先需要编译,构建语义模型,这个过程和编译器前端很相似。有了语义模型基础,语言服务器要做的就是接收客户端请求,返回数据。两者通信的过程中,使用的协议就是 LSP(语言服务器协议)。它定义了哪些智能编程能力,通信的具体内容是什么?我们下一章继续。
更多资料
我在播客 Web Worker 上和几位 Vue 生态的大佬、团队成员们聊过 Vue 插件,欢迎收听。
我也会在即刻分享语言服务器相关的开发心得,计划将它们整理成系列文章,欢迎关注。